1. DMA란?
DMA(Direct Memory Access) 는 CPU를 거치지 않고 I/O 장치가 메인 메모리와 직접 데이터 블록을 주고받게 해주는 하드웨어 메커니즘이다. OS 관점에서 보면, “장치 ↔ 메모리 복사”라는 반복적이고 대용량인 작업을 CPU에서 떼어내 병렬성과 CPU 자유도를 확보하는 핵심 최적화 기법이다.
2. 왜 DMA가 필요한가?
| 전통적 PIO(Programmed I/O)의 한계 |
DMA가 주는 이점 |
| CPU가 I/O 레지스터를 통해 바이트 단위로 옮기면 레이턴시·오버헤드가 큼 |
한 번에 수십~수천 바이트 블록을 메모리로 직행 → CPU 사이클 절약 |
| 빠른 장치(SSD, 10GbE NIC 등)는 I/O 대역폭이 CPU 속도보다 커서 CPU가 병목이 됨 |
DMA 엔진이 버스 마스터로 동작해 메모리 버스를 직접 사용 |
| 멀티코어 시대엔 CPU가 계산에 집중하고 싶음 |
CPU는 전송 시작/종료만 관리 → I/O wait 감소, 캐시 miss 감소 |
덕분에 대역폭과 지연시간을 모두 절감하며, 특히 디스크 I/O·네트워크 카드·오디오 스트리밍처럼 폭이 넓고 반복적인 전송에 필수적이다.
3. 기본 구성 요소
| 구성 요소 |
역할 |
| DMA 컨트롤러 (DMAC) |
전용 칩(고전 ISA-DMA) 또는 주변장치 내부 DMA 엔진(PCIe, NVMe). 소스/목적지 주소·전송 길이·모드·제어 플래그를 담는 레지스터를 보유하며, 채널이 여러 개면 여러 장치를 동시에 지원 |
| 시스템 버스 |
CPU ↔ 메모리 ↔ DMAC가 공유. 동시에 쓰지 않도록 버스 중재(bus arbitration) 수행 |
| 메모리 버스 |
DMAC가 버스 마스터 권한(Bus Request, BR)을 요청해 메모리와 직접 주고받음 |
| 주변장치 (Device) |
디스크, NIC, GPU, 오디오 코덱 등 데이터가 실제로 존재·필요한 곳 |
| CPU & OS |
전송 파라미터를 DMAC 레지스터에 써 주고, 완료 인터럽트(DMA done)를 처리 |
| 버스 마스터 가능 장치 |
PCIe NIC, NVMe SSD, GPU 등은 자체 DMA 엔진을 내장해 버스 마스터가 되기도 함 |
DMA 레지스터: SRC, DST, LEN
| 레지스터 |
역할 |
일반 크기 |
세부 사항 |
| SRC (Source) |
읽어올 원본 주소. 장치→RAM이면 장치 FIFO 주소, RAM→장치면 RAM 시작 주소 |
32bit(SoC) / 64bit(서버) |
버스트 여부에 따라 자동 증가 플래그 존재. Scatter-Gather 모드에선 “다음 리스트 항목” 주소로 해석되기도 함 |
| DST (Destination) |
쓰기 대상 주소 |
32 / 64bit |
자동 증가/고정 선택 가능 (오디오 DAC는 고정 주소, 메모리 버퍼는 증가) |
| LEN (Length / Count) |
총 바이트(또는 워드) 수 |
16bit(65kB) ~ 32bit(4GB) 이상 |
전송마다 LEN--, 0이 되면 인터럽트 발생. 일부 컨트롤러는 COUNT × DATA_WIDTH 형태 사용 |
요약하면, SRC·DST는 “어디서 → 어디로”, LEN은 “얼마나” 를 알려주는 좌표 + 거리 정보다.
4. 동작 흐름 (x86 PC 예시)
| 단계 |
신호선 & 동작 |
| ① CPU 설정 |
DMAC 레지스터에 〈소스, 목적지, 길이, 모드〉를 기록하고 Bus Request(BR) 활성화 |
| ② 버스 획득 |
CPU가 Bus Grant(BG)로 응답 → 버스를 놓고 다른 연산(레지스터 계산 등) 수행 |
| ③ 데이터 전송 |
DMAC가 메모리 ↔ 장치 간 버스 사이클을 생성 |
| ④ 완료 인터럽트 |
전송 길이가 0이 되면 DMAC가 CPU에 완료 인터럽트 → CPU가 버스 재획득 |
핵심: DMAC가 버스를 잡은 동안에는 메모리 버스의 주도권 전체를 갖기 때문에, CPU는 RAM에 전혀 접근하지 못한다. 개별 “주소 권한”이 아니라 “버스 소유권”의 문제다. 이 때문에 한 워드만 잠깐 빼앗고 바로 돌려주는 Cycle Stealing 모드가 등장했다.
동작 흐름 더 자세히
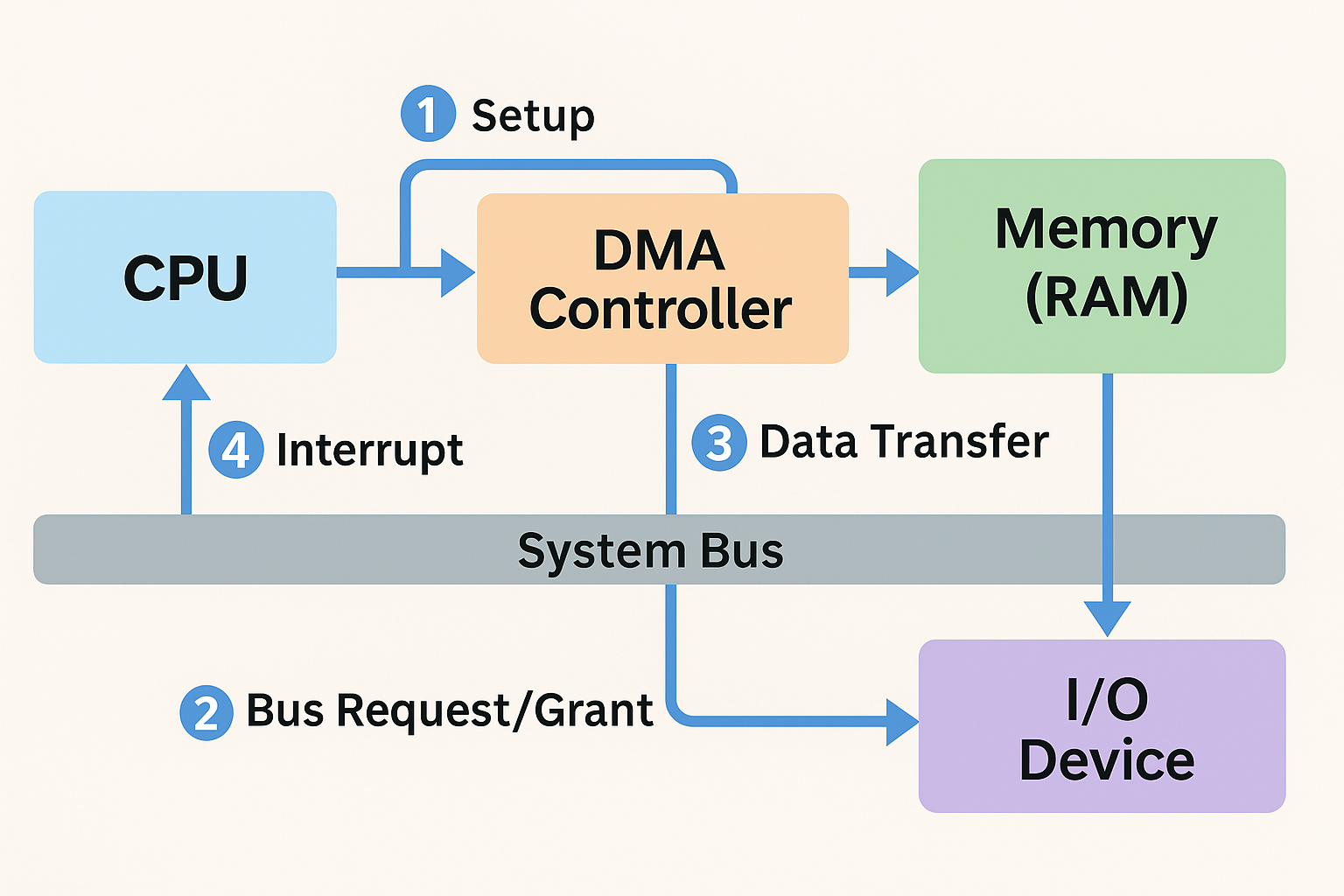
1단계 — CPU가 준비만 하고 손을 뗀다
- 전송 파라미터 설정: SRC, DST, LEN, MODE를 레지스터에 써 넣고, Enable 플래그를 1로 두면 DMAC가 “이제 내가 처리할게” 하고 대기한다
- 버스 요청(BR 신호): DMAC가 버스 중재기(arbiter)에게 “버스 좀 빌려달라”고 요청한다
2단계 — 버스 소유권 교환
- CPU → DMAC, Bus Grant(BG): CPU가 진행 중인 버스 사이클을 마치면 주소·데이터 라인을 tristate해 두고, 버스가 필요 없는 작업(레지스터·내부 캐시만으로 실행 가능한 명령)에 집중한다
- tristate: 여러 마스터(CPU, DMAC, GPU…)가 하나의 전선을 공유할 때, 한쪽이 0V·다른쪽이 Vcc를 동시에 내보내면 단락(short) 위험이 있다. 그래서 버스를 넘겨받은 쪽만 드라이버를 켜고 나머지는 Hi-Z로 물러난다
- DMAC가 버스 장악: 이 순간부터 RAM ↔ I/O 장치 사이의 모든 신호는 DMAC가 생성한다. CPU는 RAM을 못 만지므로 캐시 miss가 나면 대기해야 한다
3단계 — 실제 데이터 이동
- 전송 모드에 따른 사이클
- Burst/Block: LEN만큼 연속 전송 → 최고속, 대신 CPU가 길게 정지
- Cycle-Stealing: 한 사이클씩 “훔치고” 바로 반환 → 실시간 오디오/비디오
- Scatter-Gather: 메모리 리스트를 따라 다중 블록 자동 전송 → NVMe·NIC
- 주소·카운터 자동 증가: 내부 카운터가 0이 될 때까지
SRC++, DST++, LEN--
4단계 — 전송 완료 알림
- DMA 완료 인터럽트:
LEN == 0이 되면 DMAC가 IRQ를 날리고 버스 요청을 내린다. CPU는 인터럽트 핸들러에서 후처리(패킷 파싱, 디스크 블록 체크섬 등)를 수행한다
- 버스 복귀: Arbiter가 다시 CPU에 Bus Grant → 평상시 메모리 접근 재개
5. 전송 모드
| 모드 |
특징 |
사용 예시 |
| Single-word / Cycle-Stealing |
버스 사이클 1개만 “훔친” 뒤 즉시 반환 → CPU 지연 최소 |
실시간 오디오·비디오 스트림 |
| Block / Burst |
전체 블록을 한 번에 전송 → 가장 빠르지만 CPU 길게 정지 |
SATA, SDIO, 대부분의 PCIe 장치 |
| Demand / Scatter-Gather |
필요할 때마다, 혹은 메모리 리스트 기반 다중 블록 이동 |
고성능 NIC, NVMe SSD, GPU VRAM 업로드 |
6. 현대 시스템에서의 DMA 변화
| 기술 |
설명 |
| PCIe Bus Mastering |
주변장치가 메인 메모리를 직접 읽고 쓴다 |
| IOMMU (DMA-Remapping) |
가상화·보안 목적. 장치가 접근 가능한 주소를 OS가 테이블로 변환 → 버퍼 오염·DMA 공격 방어 |
| Cache Coherency |
CPU 캐시의 dirty 데이터와 DMA가 본 메모리가 불일치하는 문제. dma_sync_*()(Linux), 캐시 flush, non-cacheable region, snooping 버스로 해결 |
| Zero-copy |
OS 버퍼를 추가 복사하지 않고 장치 ↔ 응용이 같은 메모리 페이지를 공유. 불필요한 memcpy()를 없애 지연·캐시 오염↓ (DPDK, RDMA, CUDA cudaMemcpyAsync 등) |
| RDMA (Remote DMA) |
NIC가 원격 호스트 메모리까지 DMA 읽기/쓰기 수행. 커널 네트워크 스택을 우회해 μs 단위 지연 제공. 고속 HPC·DB 복제에 필수 |
7. 장점과 단점
장점
- CPU 사용률 감소, 전력 효율 ↑
- 대역폭 활용 극대화 (PCIe Gen4 x4 ≈ 8 GB/s 급)
- 실시간 스트리밍 지원 (오디오 스터터링 방지 등)
단점
- 하드웨어·드라이버 복잡도 증가
- 버스 우선순위 조정 실패 시 CPU 지연 가능
- 캐시 일관성, 보안(DMA 공격) 이슈 처리 필요 (IOMMU로 보완)
8. 실무 예시
| 장치 |
DMA 활용 |
| SSD / NVMe |
플래시 컨트롤러가 OS 버퍼를 읽어 NAND로 쓰기, 반대 방향 읽기 |
| 10GbE NIC |
패킷을 커널 버퍼나 ring으로 직접 놓고, 완료 시 인터럽트 |
| GPU |
대용량 텍스처·버퍼를 PCIe로 복사, VRAM ↔ CPU RAM pinned transfer |
| Audio Codec |
PCM 버퍼를 주기적으로 DMA → DAC, 실시간 재생 |
| USB 컨트롤러 |
호스트 메모리의 전송 링(Transfer Ring)을 DMA로 순회 |
9. 운영체제 관점
| OS |
관련 API / 프레임워크 |
| Linux |
dma_map_single(), dma_alloc_coherent(), struct dma_async_tx_descriptor, DMAengine 프레임워크 |
| Windows |
WdfDmaTransaction*, KeFlushIoBuffers(), Scatter/Gather 목록 지원 |
| RTOS (FreeRTOS, Zephyr) |
MCU마다 별도의 DMAMUX & HAL API 제공 |